Group rows by field values
Grouping rows in Baserow transforms flat tables into organized hierarchies; automatically categorizing your data by status, department, priority, or any field to reveal insights hidden in long lists of records.
This guide explains how to organize table data by grouping rows based on field values, creating collapsible sections that reveal patterns and relationships in your data.
Overview
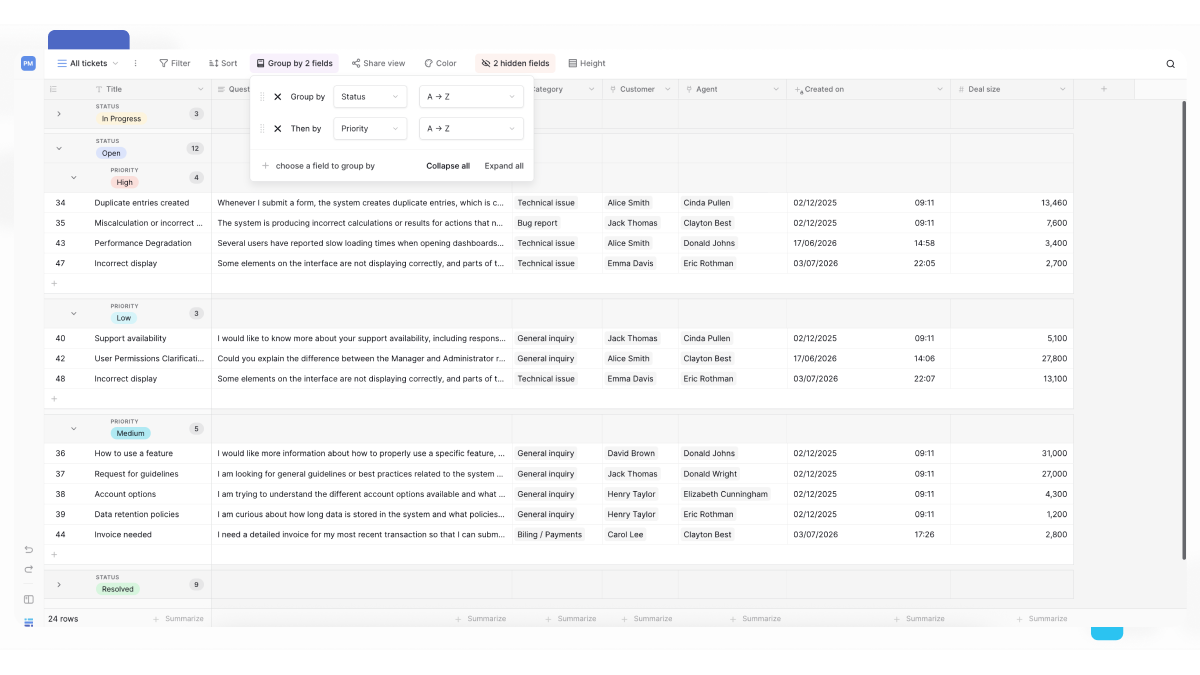
The Group by feature organizes your table rows into expandable and collapsible groups based on one or more field values, making it easier to navigate and analyze large datasets. For example, you can group tasks by Status, Assignee, or both, creating nested groups that organize related rows together. Each group can display aggregations such as counts or sums, new rows can be created directly within a group, and groups can be reordered using drag and drop. You can group by up to five fields, helping you organize data in multiple levels without losing context.
Groups update automatically as your data changes. Add a row with a new status value, and Baserow creates a new group instantly. You can nest multiple levels of grouping to create hierarchies like Department → Team → Priority, revealing patterns across multiple dimensions simultaneously.
Grouping works exclusively in Grid View and complements filtering and sorting to give you powerful data organization without formulas or complex configurations.
When to use row grouping
Project management: Group tasks by Status to see what’s In Progress, Blocked, or Complete. Add a second-level grouping by Assignee to see each person’s status breakdown.
Sales pipeline: Group opportunities by Stage (Prospecting, Negotiation, Closed) to visualize your pipeline. Nest by Sales Rep to see each team member’s pipeline distribution.
Inventory management: Group products by Category, then by Supplier to understand your inventory structure and supplier relationships.
Event planning: Group registrations by Event Date, then by Ticket Type to see attendance patterns and revenue distribution.
Customer support: Group tickets by Priority, then by Department to identify workload distribution and urgent items requiring attention.
Grouping vs. filtering vs. sorting
| Feature | Purpose | Result | Rows visibility |
|---|---|---|---|
| Grouping | Organize into categories | Collapsible groups with aggregations and nested grouping | All rows organized into groups |
| Filtering | Show subset of data | Hide rows not matching criteria | Only matching rows visible |
| Sorting | Change row order | Rows arranged by value | All rows visible in order |
| Combined | Focus and organize | Filtered data in organized groups | Only matching rows, grouped |
Compatible field types for grouping
| Field type | Groups by | Example grouping |
|---|---|---|
| Single select | Each option | Status: To Do, In Progress, Done |
| Multiple select | Each selected option (rows may appear in multiple groups) | Tags: Marketing, Sales, Product |
| Collaborator | Each person | Assigned to: Alice, Bob, Charlie |
| Link to table | Each linked record | Customer: Acme Corp, TechCo, etc. |
| Boolean | Checked/Unchecked | Completed: Yes, No |
| Date, Duration, Last modified and Created on | Date values | Due Date: 2025-01-15, 2025-01-20, etc. |
| Text, URL and Email | Exact text matches | Department: Engineering, Sales, Support |
| Number, Count, Phone number and Rating | Exact number values | Priority: 1, 2, 3 |
Note: Formula fields, lookup fields, and other computed fields can be used for grouping based on their result type.
How to add a group
Create your first group level to organize rows by a single field. You can group by up to five fields, creating nested groups within groups.
To group rows:
- Open your table in Grid View
- Click the Group button in the view toolbar
- Select Choose a field to group by from the dropdown
- Choose the field you want to group by
Rows immediately reorganize into collapsible sections based on the field’s unique values. Each section header shows the value name and row count.
How to add multiple group levels
Create nested groups (subgroups) to reveal hierarchical patterns in your data.
To add a second group level:
- After creating your first group, click Choose a field to group by again
- Select a second field from the dropdown
- Rows within each first-level group are now divided into second-level subgroups
Example: Group by Department (first level), then by Priority (second level) to see each department’s priority breakdown.
To add more levels: Repeat the process to create third, fourth, or more nesting levels. Each level creates subgroups within the previous level’s sections.
How to manage groups
Expand and collapse groups
Groups are collapsed by default, making it easier to navigate large datasets.
You can:
- Expand an individual group to view its rows.
- Collapse a group to hide its contents.
- Expand or collapse nested groups independently.
- Use Expand all or Collapse all to quickly change the visibility of every group.
Collapsed groups display their row count and any configured summary values, making it easier to navigate large tables.
Reorder group levels
Re-order group by fields using drag and drop.
The order of group levels determines the hierarchy. The first field creates the top-level groups, while each additional field creates nested subgroups.
For example:
- Status → Assignee groups tasks by Status first, then by Assignee.
- Assignee → Status groups tasks by Assignee first, then by Status.
Remove a group level
Click the X button next to any group in the Group panel to remove that grouping level. Removing a middle level shifts the lower levels up in the hierarchy.
Change a group field
Click a group field in the Group panel and select a different field from the dropdown to replace it. The view instantly regroups using the new field.
The top field always creates the primary grouping, with subsequent fields creating nested subgroups.
Clear all groups
Remove all group levels by clicking the X button on each group, or close the Group panel and click “Clear all” if available. Your table returns to a flat list view.
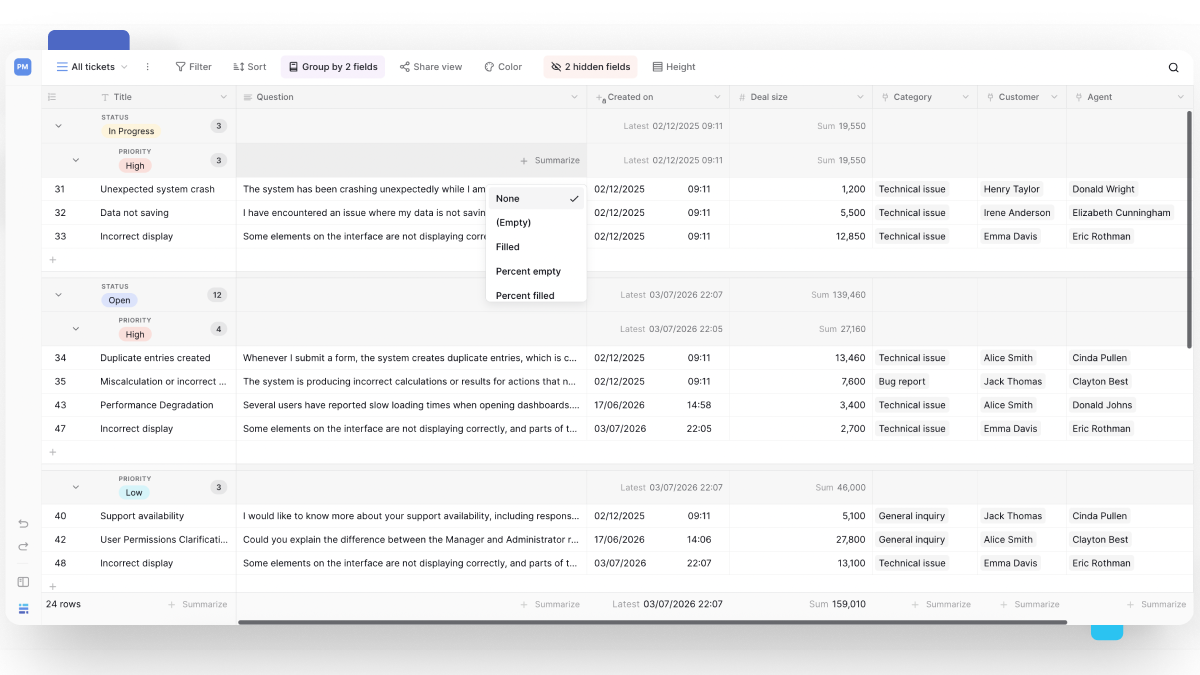
Group summaries and counts
Each group header displays the number of rows it contains. You can also configure field summaries that are calculated separately for each group.
In addition to row counts, you can display the same calculations that are available in table footers, calculated separately for each group.
Depending on the field type, available summaries include:
- Count
- Empty / Not empty
- Sum
- Average
- Minimum
- Maximum
- Median
- Standard deviation
- Variance
- Unique values
Group summaries update automatically whenever rows are added, edited, or deleted.
Combining grouping with filters and sorts
Grouping works alongside filtering and sorting to create powerful data views:
Grouping + Filtering: Apply filters first to show a subset of rows, then group the filtered results. Example: Filter to show only “Open” tickets, then group by Priority.
Grouping + Sorting: Sort rows within each group alphabetically, numerically, or by date. Groups maintain their structure while rows inside sort independently.
Grouping + Both: Create focused, organized views by filtering unwanted rows, grouping the results into categories, and sorting within each group. Example: Show this quarter’s sales (filter) → grouped by Region → sorted by Deal Value descending.
How grouping affects multiple select fields
Multiple select fields behave differently when used for grouping because rows can have multiple values selected.
When you group by a multiple select field, rows appear in every group corresponding to their selected values. A task tagged with both “Marketing” and “Sales” appears in both the Marketing group and the Sales group.
This differs from single select grouping, where each row appears in exactly one group. Be aware that group row counts may exceed your total row count when grouping by multiple select fields.
Frequently asked questions
Can I group by formula fields or lookup fields?
Yes, you can group by any field type, including formulas and lookups, as long as the field produces a groupable value. The grouping uses the calculated or looked-up result values to create groups.
What happens to rows with empty values when grouping?
Rows with empty values in the grouped field appear in a separate “(Empty)” group at the top or bottom of your view. This makes it easy to identify records with missing values in important fields.
Do groups affect my data or just the view?
Grouping only affects how you view data; it never changes your underlying data. Remove all groups and your original table structure remains intact. Each view can have different grouping configurations.
Does grouping slow down my table?
Grouping adds minimal performance impact for most tables. Very large tables (100,000+ rows) with multiple group levels may take slightly longer to render, but Baserow’s lazy loading ensures smooth scrolling and interaction.
Can I export grouped data with its group structure?
When you export a view, the data exports in flat format without group structure. However, rows appear in the order they’re displayed in groups, so you can see the grouping sequence in your exported file.
How many fields can I group by?
You can group by up to five fields, creating nested groups that help organize your data across multiple levels.
Related content
- Grid View guide - Learn about Grid View features and capabilities
- Filter rows - Combine filtering with grouping for focused views
- View customization - Explore other view configuration options
- Field summaries - Add calculations to grouped data
- Create custom views - Design views optimized for specific grouping needs
- Rows overview - Understand how rows work in Baserow
Still need help? If you’re looking for something else, please feel free to make recommendations or ask us questions; we’re ready to assist you.
-
Contact support for questions about Baserow or help with your account
- On this page
- Overview
- When to use row grouping
- Grouping vs. filtering vs. sorting
- Compatible field types for grouping
- How to add a group
- How to add multiple group levels
- How to manage groups
- Group summaries and counts
- Combining grouping with filters and sorts
- How grouping affects multiple select fields
- Frequently asked questions
- Related content